摘要
本文基于动态分析框架Jalangi实现了轻量级的变更感知动态程序分析工具,并使用DLint和JITProf工具中的46个检测器进行评估,结果表明总体分析时间平均减少了40%,大概31%的commit能减少80%
1. 介绍
大多在通用分析框架上实现的动态分析,比如Valgrind和Jalangi,强大但重量级。通常这种分析有很大的运行时开销。大型回归测试套件的项目在动态语言中很常见,静态检测很稀疏且可能会有遗漏。例如,使用JavaScript的两种动态分析工具DLint和JITProf运行underscore.js库的回归测试套件需要5分钟,如果不进行分析只需要5秒

给了个例子,测试调用a, b, e,变更后的动态分析会执行所有代码,但是大多代码不受变更影响,所欲不用重新分析未受影响的代码
减少动态分析开销的现有方法有抽样:
- 以特定的方式对执行进行抽样,例如基于代码位置的执行频率进行采样
- 将检测开销分配给多个用户
作为一种补充减少动态分析开销的技术,回归测试可以减少执行测试的数量,从而减少整体分析时间。回归测试选择部分解决了已有的问题,但是也有缺点:即使在约减了测试用例的数量后,分析可以也会考虑未受变更影响的代码,例如上例中调用b会触发对d的动态分析,但是d不受更改的影响
本文解决减少运行动态分析的时间的问题,这些动态分析在之前版本的分析代码中已经应用过。本文提出了change-aware dynamic analysis(变更感知的动态分析),缩写为CADA,这个方法将一类动态分析转化为变更感知分析。关键思想是通过关注受代码变更影响的函数约减动态分析的代码位置数。在运行时进入函数时,只有这个函数受到影响才对其进行分析,在实际中发现,大多代码只影响一小部分函数,使CADA能避免分析大多数函数
要查找更改影响的函数,轻量级的变更影响分析会根据读写操作确定函数之间的依赖关系并产生函数依赖图。从特定变更修改的函数为起点,将影响传播到所有可能受影响的函数
对于上图的示例,a已更改,并且由于这个更改,函数c也受到影响
为了评估CADA方法,应用这个方法到七个流行的JavaScript项目的历史版本,不使用本文的方法进行变更分析需要平均需要133秒(commit之间)。CADA平均减少了40%的分析时间,其中31%的commit至少减少了80%的分析时间。CADA和非变化感知分析比较,它不会遗漏针对动态分析报告的任何警告
本文贡献:
- 将普通的动态分析转换为变更感知动态分析而不需要修改分析本身
- JavaScript的一种轻量级的静态变更影响分析。分析可以帮助做其他很多事,比如帮助开发者了解变更潜在的影响和测试用例的优先级
- 实证证据表明方法大大减少了使用重量级动态分析的时间,变得易于使用
2. 问题陈述
给定程序$P$和输入$I$,动态分析$A$产生一系列警告$A(P, I) = \mathcal{W}$,每个警告都是一个pair,包含代码位置$l\in\mathcal{L}$和描述$d\in\mathcal{D}$,也就是说$\mathcal{W}=\mathcal{L}\times\mathcal{D}$,举个例子,图1中的警告可以表示为$(line\ 22$,”$NaN\ created$”$)$。
本文重点关注动态分析,识别特定警告,通过一组局部受限的代码位置寻找触发运行时事件的原因。我们将次称为局部受限动态分析(locally confined dynamic analysis)。这类动态分析不包括分析整个程序跟踪值的分析,比如信息流分析和全程序依赖分析
局部受限动态分析和本文所做的变更感知分析的区别(个人理解):
- 局部受限动态分析侧重动态分析框架,没有过去版本分析的信息,也就没有过去版本生成调用图的信息,运行测试用例该怎么跑就怎么跑,没有对路径的剪枝
- 变更感知分析更侧重根据变更所影响的函数调用图约减测试的函数,达到减少时间开销的目的
在开发过程中,程序通过变更演化,另$P, P’, P’’$表示程序的不同版本。我们工作目标是对开发过程中出现的每个新版本应用动态分析,以便开发人员能够立即对最近更改引起的任何警告做出反应。对于从$P$到$P’$的变化,假设有一个映射$\mu:\mathcal{W}\rightarrow\mathcal{W’}$表示这个变更导致的警告的变化。
有三种警告:
- 老警告在新版本中保留下来:$\mathcal{W}_{old}=\{w’\in\mathcal{W’}|\exists w\in\mathcal{W}\text{ so that }\mu(w)=w’\}$
- 引入新警告:$\mathcal{W}_{new}=\{w’\in\mathcal{W’}|\nexists w\in \mathcal{W}\text{ so that }\mu(w)=w’\}$
- 老警告被修复:$\mathcal{W}_{fixed}=\{w\in\mathcal{W}|\nexists w’\in \mathcal{W’}\text{ so that }\mu(w)=w’\}$
一个简单但是计算代价大的方法是在每个版本上计算这样一组警告:
本文要解决的就是如何减少局部受限动态分析的时间,在之前的版本已经分析过之后。也就是说是要提出一种变更感知的分析方法$A_{CA}$,满足以下两个属性:
与完整分析相比,第一个条件保证不会遗漏新警告和保留下的警告,第二个条件保证时间开销减少
3. 方法
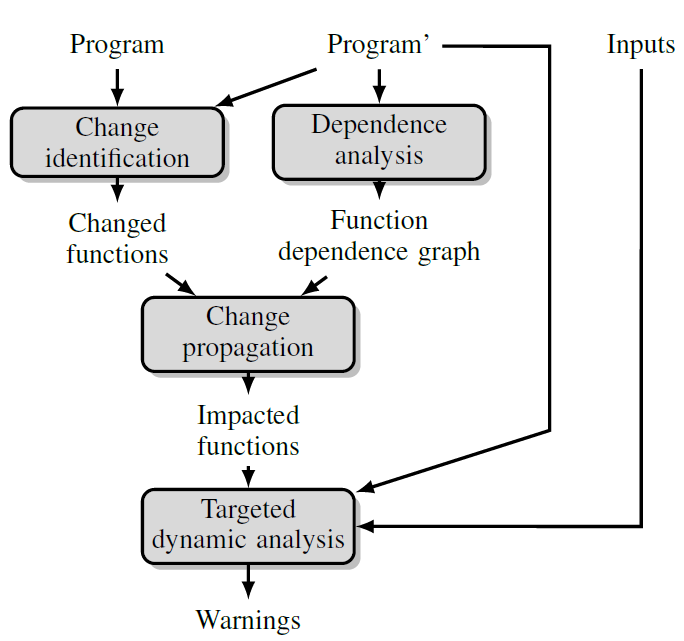
为了解决这个问题,提出了CADA,这种方法将局部受限的动态分析转化为变更感知分析。该方法的核心是静态变更影响分析。在给定程序的两个版本下,确定可能手变更影响的代码位置集合。变更影响分析包括三个步骤:
- CADA分析两个版本之间的差异,以确定修改后的代码位置集合,这一步纯粹是语法上的,没有推断变化的影响
- 对修改程序进行依赖分析提取出代码位置之间的依赖关系图
- CADA通过依赖图传播代码位置修改的信息,计算所有受变更影响的代码位置
- 最后将受影响的代码位置集合提供给动态分析,动态分析分析修改的程序,关注受影响的代码
一个重要的设计决策时确定在哪个级别的粒度上计算变更影响和动态分析的代码位置。三个可能的选择是:文件级别,函数级别,语句级别。文件级别的方法将每个源代码文件确定是否有任何代码受到更改,然后对受影响文件的所有代码进行动态分析,这个粒度的分析缺点在于单个文件可能包含大量代码,因此该方法可能分析不必分析的大量代码
语句级别的方法计算所有语句间的依赖关系,然后进分析受变更影响的语句。尽管这种分析在三个选择中是最精确的,但是考虑到计算成本,放弃这个方案。CADA最终的目的是减少时间开销,精确计算所有语句级别的依赖关系可能需要花费大量时间处理复杂的程序
为了平衡精度和计算成本,CADA计算函数级别的依赖关系,也就是说,静态变更影响分析确定哪些函数收到了变化影响,而动态分析仅选择性地分析受影响的函数
A. Change Identification(变更识别)
CADA的第一步就是比较原始程序和修改后的程序,以确定语法修改的函数集。首先,该方法使用diff计算修改后的程序那些行被修改。这些行还包括新添的行。接下来,该方法吧变更的程序转化为AST并用dfs的方法遍历AST。遍历期间,CADA访问到代表函数的所有节点,跟踪每个函数开始和结束的代码位置,最后,在遍历程序的所有文件的AST之后,方法将每个修改的行匹配到改行对应的最内层的函数,并且报告具有至少一个更改行的函数作为变更的函数
对于给的例子,第4行识别为修改的行,遍历完后函数a被识别为改变的函数
B. Dependence Analysis(依赖分析)
为了计算受影响的函数,首先要计算函数间的依赖图:
定义1 (函数依赖图) :函数依赖图是一个有向图$G_{dep}=(\mathcal{N}, \mathcal{E})$。其中每个节点$f\in\mathcal{N}$表示函数,$(f_1, f_2)\in\mathcal{E}$表示函数$f_2$依赖于$f_1$,即$f_1$影响了$f_2$
CADA考虑函数依赖图的两种依赖关系:
- 定义-使用依赖关系,表示函数读取可能在另一个函数中定义的值
- 调用依赖关系,表示一个函数可能被另一个函数调用
这两种依赖图式表示为$G_{DU}$和$G_C$,总体的调用图是两个图的并
定义-使用依赖:建立在程序内,流不敏感分析代码位置间的读写关系,具体地,给定一组代码位置$\mathcal{L}$,分析提取出定义-使用二元组$(d, u)$,其中$d,u\in\mathcal{L}$,$d$写入了可能被$u$写入的值
CADA通过两个映射获取定义-使用分析的结果。第一个是映射$\mathit{usesOf}:\mathcal{L}\mapsto 2^{\mathcal{L}}$,从一个代码位置映射到一组可能读取这个值的代码位置。第二个映射是$\mathit{defsOf}:\mathcal{L}\mapsto 2^{\mathcal{L}}$,从一个代码位置映射到一组可能定义了这个值的代码位置
为了计算程序的函数级别的定义-使用依赖,CADA遍历程序所有把值写入内存的代码位置,对于这样的位置$d\in\mathcal{L}$,可以分析计算读取该值的位置$\mathit{useOf(d)}$。接下来使用辅助映射$\mathit{fctOf}:\mathcal{L}\mapsto \mathcal{F}$将这些位置映射到函数,最后分析在图$G_{DU}$上加入函数级别的表示定义-使用的边,对于每个$u\in\mathit{usesOf(d)}$,都有一条$\mathit{(fctOf(d), fctOf(u))}$边
调用依赖:对于每个被函数$f_{caller}$调用的函数$f_{callee}$,分析会创建两种依赖边。首先,增加了一个$(f_{caller},f_{callee})$因为$f_{caller}$上的改动会影响$f_{callee}$的调用;其次,还会加一条$(f_{callee},f_{caller})$边,当且仅当$f_{callee}$返回值给$f_{caller}$。为了解析函数调用,CADA通过$\mathit{defsOf}$查询函数定义位置
有效地计算依赖:本文使用静态分析构建依赖关系。静态分析得到精确的结果是不可能的,同时也为了考虑到时间开销,分析不对with结构,eval动态加载的代码,动态计算的属性名和getter与setter的副作用进行处理
分析将程序转换为AST并遍历三次AST计算依赖。前两次遍历计算定义-使用二元组,得到$\mathit{defsOf}$和$\mathit{usesOf}$映射
基于这俩映射,第三次遍历计算函数级别的定义-使用关系
C. Change Propagation(变更传播)
基于函数依赖图,CADA通过图传播源代码变更的影响。首先,该方法标记所有已更改的函数,然后再函数依赖图中通过以来便计算标记节点的传递闭包。最终标记了源代码变更直接或间接影响的所有节点。CADA将与标记的节点对应相关的函数标记为impacted functions
D. Targeted Dynamic Analysis(有导向的动态分析)
CADA在执行分析的程序进入函数时,会检查是否需要分析该函数。若该函数不受变更影响,则不对函数体进行分析,即,变更感知方法避免了此函数的分析开销
函数级别选择分析代码有以下优点:
- 每个功能在执行前检查是否分析
更细粒度的选择分析,比如在个体表达式的级别,将有更多检查,但是每次检查都会产生额外的运行时开销,所以过于细粒度的选择分析会破坏选择分析特定代码位置的目的
E. Reporting Warnings(报告警告)
使用有导向的动态分析进行变更后版本程序的分析后,CADA报告所有检测到的以及在之前版本发现到的警告。为了在版本之间进行映射,本文使用Unix “diff”工具从之前版本映射到更改后的版本。但是先前版本的警告可能是不正确的,因为变更可能修复了警告。为了减少/避免这种误报,我们仅映射先前检测到的警告,这些警告在未受变更影响的函数中。这些警告没有通过变更修复,所以他们从之前版本开始传播是正确的。相比之下,受影响的函数的所有警告都通过动态分析来检测,不必从先前的警告中映射它们
4. 实现
实现CADA用于动态分析JavaScript代码
静态变更影响分析工具基于Esprima(用于语法分析)和Tern(用于计算定义-使用信息)。静态分析的输出是在动态分析时需要分析的函数列表。选择动态分析在Jalangi上实现。它支持通过生成每个函数体上的两个变体进行函数级别上的选择分析:一个是原有代码,另一个是插桩后的代码。然后项目开源
7. 结论
本文展示了变更感知分析,可能极大地约减运行时动态分析的开销,通过关注受代码改变影响的位置
我们在46个动态检测器上检测7个广泛使用的JavaScript项目源码来评价CADA。我们的结果显示平均减少40%的分析时间,其中31%的commit减少至少80%的时间