摘要
除了展示fuzzer找到bug外,很少有系统化的工作来理解如何恰当地fuzz。
本文就是要系统化地说明:如何选择种子文件来最大化fuzz阶段发现bug的数量。
本文设计了6个算法,fuzz了650个CPU天,在8个应用上发现了240个bug,结果显示挑选算法的选择可以很大地增加发现的bug。
1 介绍
2012年,软件安全市场估值$19.2billion。
给定目标应用$P$,一系列的种子输入文件$S$,程序员需要:
让程序$P$读入文件
确定应用的相关文件类型,PDF viewer读入GIF图像就可能不会发现太多bug
- 选择$s’\in S$来fuzz程序。这里就需要进行种子输入选择。有两种专用的种子输入选择方法:1. 找到已可用的输入 2. 通过代码覆盖找到最小的种子输入集合
- fuzz loop
在整个文章中以最大化unique bugs为最大目标。对于fuzzer类型没有假设,随便是黑盒白盒等。在实验中使用了BFF,一个常用的fuzzer。我们的技术也没有对fuzz调度算法进行特别的假设。为了评价种子选择策略,我们使用使用了常用的调度算法round-robin和最大可能性调度。
本文实现一个系统COVERSET。目标是在有限的时间内最大化地找到bug
然后提出三个问题:
- 对于百万,十亿,一万亿的PDF文件,能否从高中选出合适的$S’\subseteq S$去fuzz
- 如何确保种子选择和fuzzing调度的独立性?举个例子,有种子输入集合$S_1$和$S_2$,$S_1$最大化了bug,但是$S_2$在更智能的调度算法下找到更多的bug,能否建立一套理论,说明一个种子输入集合在最有可能的fuzzing策略下比其他输入集合好
- 对于某种类型的文件类型是否有一个足够好的种子输入集合用来对所有类似程序进行fuzzing,这样只需要计算一次约减测试用例就可以了
本文主要贡献就是回答了以上的问题,然后总结一下本文的主要贡献:
- 我们形式化,实现并测试了一些列存在且新颖的种子选择算法
- 形式化地确定了最优化种子选择的概念,提供一个优化算法,即使不同种子发现的bug是相关的
- 开发了一个证据驱动的技术来识别种子选择测试的质量
- 在8个广泛使用的应用上找到240个unique bugs
2 Q1:种子选择
如何为fuzzer选择seed files。下载了4,912,142个不同的文件和274种不同的文件类型。如何约减测试数量是个重要的问题。
已有的工作提出基于代码覆盖的种子选择策略。已有的工作表明覆盖率与发现bug之间存在关联,但是没有对不同的方法进行比较,或者评价哪个最优。
set cover problem(SCP)问题给定一个集合$X$和一个子集的有穷列表$\mathbb{F} = \{S_1, S_2,\dots, S_n\}$,$X=\cup_{S\in \mathbb{F}}S$。有一个集合$\mathbb{C}\subseteq\mathbb{F}$是$X$的集合覆盖当:$X=\cup_{S\in \mathbb{C}}S$。
minimal set cover problem(MSCP)的任务就是找到$\mathbb{C}\subseteq\mathbb{F}$使$\mathbb{C}$最小化,但是这个$\mathbb{C}$不一定是唯一的。
所以除了覆盖率,还需要考虑其他属性,比如执行速度,文件大小等。这个集合覆盖问题对于$S\in\mathbb{F}$都有一个权重$w(S)$。那么对于集合覆盖$\mathbb{C}$的代价计算为:$Cost(\mathbb{C})=\sum_{S\in\mathbb{C}}w(S)$。这个weighted minimal set cover problem(WMSCP)的目标就是找到代价最小的覆盖集合,也就是说$argmin_{\mathbb{C}}Cost(\mathbb{C})$。
以下是一个WSCP的最优化贪心多项式时间近似算法
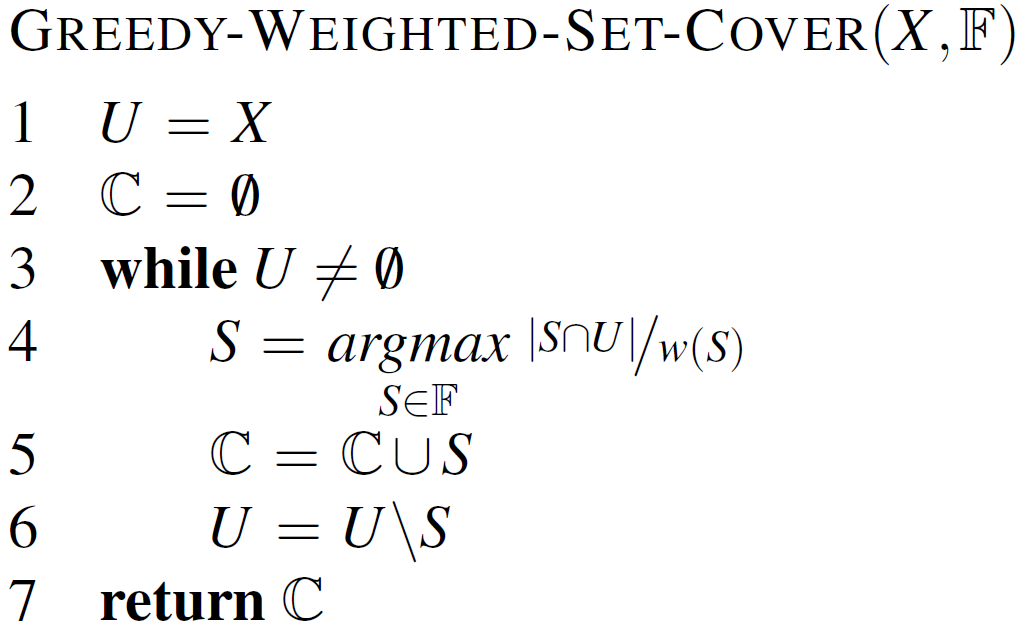
无权重的条件下可以设置$\forall S: w(S)=1$
2.1 种子选择算法
本章中使用Peach中的集合覆盖算法,通过执行时间和文件大小进行带权的集合覆盖最小化
这里给出比较的6种种子选择算法有相同的输入文件集合$\mathbb{F}$。最后要约减到k个文件,$k\ll |\mathbb{F}|$,时间限制为t秒。
PEACH SET。 Peach有一个类MinSet计算覆盖集合$\mathbb{C}$:

大致意思就是计算每个测试用例的覆盖率,然后排序,若$\mathbb{C}$没有覆盖当前测试用例的所有基本块,则包含该测试用例并更新$\mathbb{C}$
RANDOM SET。 直接随机选择k个种子作为输入。。。作为其他算法的baseline。为了减少随机性带来的偏差,跑100次选择中位数
HOT SET。 每个种子都fuzz个t秒然后返回找到unique bug最多的k个种子输入。
UNWEIGHTED MINSET。 没看懂是啥。。好像就是不考虑权重地找一个最小k集合
TIME MINSET。 返回执行时间权重的最小k集合
SIZE MINSET。 返回文件大小权重的最小k集合
3 Q2: Measuring Selection Quality
需要评价上面这些输入选择算法的性能
假设算法A选择测试集合$S_A$,算法B选择测试集合$S_B$,然后再这两个集合上fuzz相同的时间,找到更多unique bug的测试输入集合更优,即对应的选择算法更优
3.1 形式化
$Fuzz$是一个单线程的Fuzzer,输入为种子输入$\mathbb{C}\subseteq\mathbb{F}$和一个时间阈值$t_{thres}$,输出unique bugs $b_i$的序列,及其对应的种子输入$S_i$和时间戳$t_i$
这里把最优化种子调度问题形式化为一个整数线性规划(ILP)问题
首先创建一个指示变量
然后再来一个指示变量表示种子i是否包含了$j^{th}$ crash
多个不同的$c_{i,j}$可能由同一个bug引发,所以这里再引入一个函数$\mu$,相当于对这些crash进行哈希
最后要计算发现每个bug的时间代价:
其中$a_{i, j}$表示$c_{i,j}$的发生时间,$t_{i,j}$表示时间间隔,然后就可以把调度问题形式化为ILP问题了:
最大化找到的unique bug就完事了,再加一个约束bound一下最小集合的大小$\sum_i c_{i,1}\leq k$
Round-Robin最优化种子选择。
这个条件保证了每一个种子的探索时间都有一个upper bound $\frac{t_{thres}}{k}$
4 种子文件的转让(?)
预计算单个应用$P_1$的种子集合是时间密集的。举个例子,基于最小集合的方法第一步是动态运行每个种子收集覆盖信息。收集这些信息代价可能很大。在本文的实验中,收集覆盖信息消耗了7小时。一个想法就是在已有的这些种子上找到“好的”输入集合,然后再其他应用上复用,以最小化总体的代价
举个例子,如果$P_1$和$P_2$都使用了poppler这个PDF库,那么这两个程序都很有可能在同样的输入上出错;也有另一种可能,他们使用了不同的PDF库,但是在PDF本质上很难正确实现某个功能,然后就一起出错了。这些问题之前没有工作进行系统的调查
5 系统设计
假设测试程序P,那么为了fuzz,我们需要:
- 了解P的命令行参数
- 确认哪些参数能够令程序P读入文件/输入
- 确定合适的输入文件类型
找这个参数首先使用了启发式的方法,也就是说通过常用的命令行参数来接受文件,比如-f file。同时也通过-help来了解如何输入文件
在收集到的数据集中有274种文件类型,如何确定程序P接受那种类型的文件成了问题。本文基于以下假设提出一个近似的识别方法:如果s是P可接受的文件类型,而s’不是,那么期望的覆盖率P(s)>P(s’)
首先创建一些列文件类型的种子F,然后对于$s_i\in F$,计数$P(s_i)$执行的基本块数,最后选择运行基本块数最多的文件类型
6 实验
实验设置。实验用的fuzzer是CERT Basic Fuzzing Framework(BFF)
6.1 构建Ground Truth
选择了10个应用和5种常用文件格式
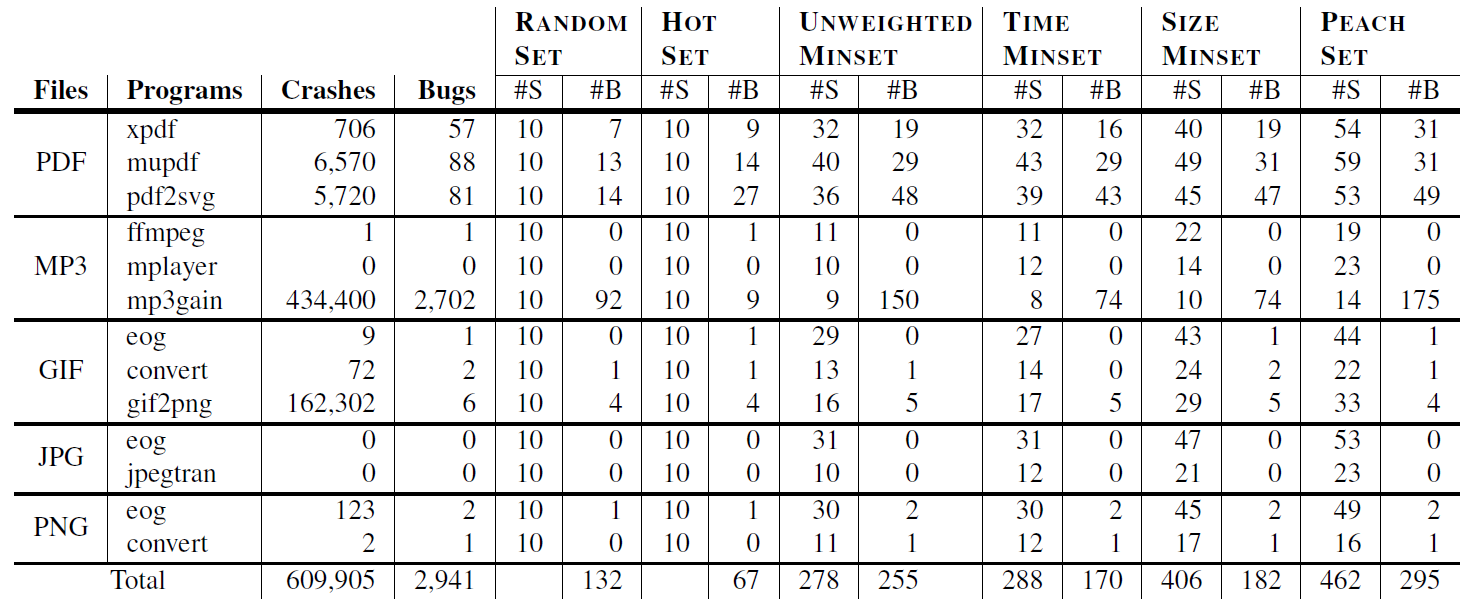
保证每种文件类型都至少有两种不同的应用去执行
种子文件。随机采样100个种子文件,确定单个种子的ground truth需要12小时
Fuzzing参数。
Fuzzing结果。找到了2941个unique crashes。10个应用中的8个有crash。其中2,702个unique crash在mp3gain中找到。人工审查后发现造成这些crash的根源是一个缓冲区溢出漏洞。BFF找到240个bug——2941-2702+1
6.2 种子选择算法比随机采样更好吗?
过程有点看不懂。。直接上结论:种子选择算法有一定的帮助
6.2.1 哪个算法性能表现最好
还是结论:无权重的最小化集合算法性能最好
6.2.2 约减后的种子集合比全集好吗?
结论:在约减后的集合上fuzzing效果大大滴好
6.3 约减后的集合可以跨程序重用吗?
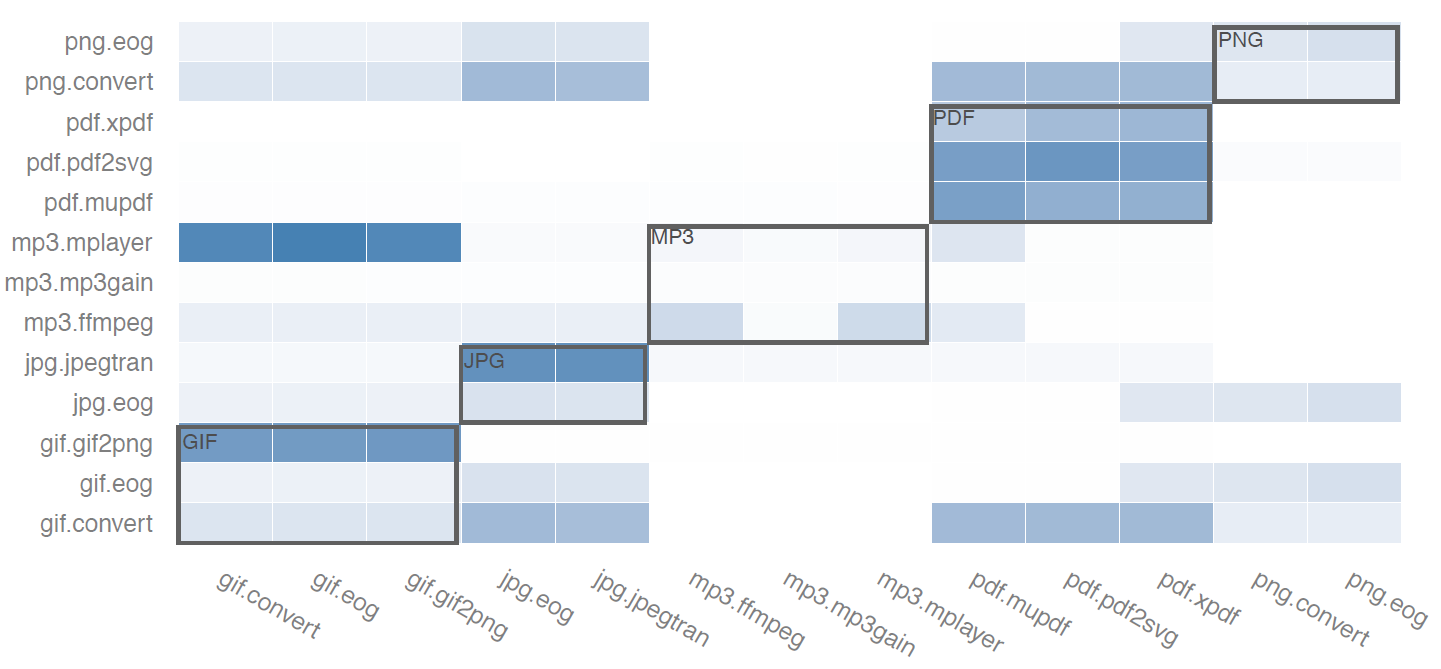
热力图颜色越深表示横轴程序在对应纵轴的项目上达到了更高的覆盖。
结论:约减后的集合可以迁移到其他程序使用
6.4 推断文件类型
之前提到启发式的方法推断程序接受的文件类型,现在人工验证准确性。
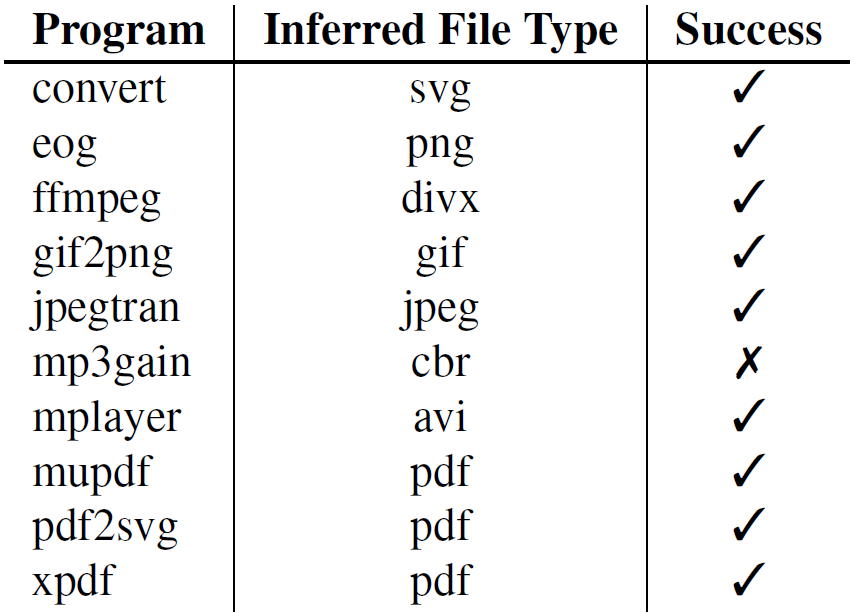
除了一个之外都识别对了,识别效果还是很好的。
7 讨论和未来工作
8 相关工作
9 结论
本文设计了6种种子选择技术,此外还把最优的种子选择调度问题形式化为一个整数线性规划问题来度量种子选择算法的性能。然后通过650天的fuzzing确定ground truth values和评价每个算法。找到了240个新bug。本文工作对如何进行种子选择算法的输入来最大化发现bug数提出了指导建议。