FairFuzz: A Targeted Mutation Strategy for Increasing Greybox Fuzz Testing Coverage
摘要
本文提出了FAIRFUZZ,从两个方面改进AFL:
- 自动化识别很少被输入hit的分支
- 提出创新的mutation mask创造算法,使生成的输入能够hit给定的rare branch
1 介绍
本文的主要贡献:
- 提出一个新颖的mutation mask策略来增加hit rare branch的概率
- 基于AFL,将上述策略集成到AFL上,实现FAIRFUZZ并开源
- 以AFL为baseline,将FAIRFUZZ与之进行比较评价效果
2 概览
2.1 AFL概览

主体流程:
- 生成种子输入$Seeds$,传递给队列$Queue$
- $Queue$中取出一个$input$
- 若该输入不值得fuzzing,则回到2
- 否则为这个输入进行打分,得到$score$
- 对于$input$的长度$|input|$(byte长度),根据所有不同的确定性变异策略进行变异(策略包括翻转bit,翻转byte,整数值的算术加和减,用感兴趣的整数值,如0,MAX_INT等替换bytes等),在新输入上运行测试用例,保存运行结果,若产生了新的覆盖,则把输入加到$Queue$中
- 根据得到的$score$,对输入进行$\textit{MUTATEHAVOC}$变异,$\textit{MUTATEHAVOC}$是在$[1,256]$中采样一个变异次数$num$,使用随机变异策略在$input$的随机位置上进行变异(策略包括设置bytes为随机值,删除或拷贝输入的子序列等),执行$num$次,在新输入上得到运行结果
- 重复步骤2~6
2.2 AFL覆盖率计算
AFL使用基本块作为基本单位,然后使用一个唯一的$ID$记录这个基本块,基本块之间的转换$A\rightarrow B$关系用下式表示
2.3 AFL的局限性
2.4 FAIRFUZZ概览
从直觉上来说,被少数输入击中的分支守卫代码比被大量生产的输入命中的分支保护的代码更不可能被彻底探索。
主要识别输入中不可变异的部分以击中很少执行的分支,使输入保持满足很少执行分支的条件。
3 FAIRFUZZ算法
3.1 变异Masking
Definition 1. 一个变异用二元组$(c, m)$表示,含义为m个字节被变异影响,c是变异的种类:
- O:重写从位置k开始的m个字节
- I:在位置k插入m个字节
- D:在位置k删除m个字节
Definition 2. 已有输入x和测试目标T,函数$mask_{x, T}$定义为$mask_{x, T}: \mathcal{N}\rightarrow\mathcal{P}(\{O, I, D\})$,输入为输入x中的位置i,输出返回$\{O, I, D\}$的子集。若$satisfies(mutate(x, (c, 1), i), T)$,则$c\in mask_{x, T}(i)$。对于$mask_{x, T}(i)$中的c,在采取策略c变异后依然能够满足T:
大致意思就是改变输入x的$[k, k+m-1]$这个区间后,依然能使T满足的变异种类,那么这个种类c就是OK_TO_MUTATE的。

3.2 稀有分支导向
3.2.1 选择变异的输入
Definition 3. $hits(x, b)$表示输入x经过分支b的次数
Definition 4. $\mathcal{I}$表示由fuzzing产生的输入。那么分支b的hit count为:
一开始的想法是指定阈值和选择少于$p\%$的输入作为rare。但是初步试验后,拒绝了这个方法:
- 设阈值为5,但是最少的分支也有20和15000输入hit
- 这些阈值根据不同的benchmark需要修改,不能动态调整
Definition 5. 另$B$为程序中所有分支的集合,$B_v = \{b\in B: numHits[b]\gt 0\}$。那么一个分支b如果是rare branch应该满足:
其中:
Definition 6. 另$branches(x) = \{b\in B:hits(x, b)\}$。那么输入x击中路径中的击中次数最少的称为rarest branch,记为$b^*$。
FAIRFUZZ的选择只选择输入中rarest branch是rare branch的进行变异(算法2中的第5行)
虽然只使用上述策略,FAIRFUZZ也会使用AFL的默认策略运行几个cycle。
3.2.2 计算变异mask

3.3 测试目标导向的输入剪枝
AFL采取两个技术保持输入的简短:
- 短输入优先选择
- 在变异前进行剪枝
剪枝后的输入最小化需要变异的输入,约束是最小化后的输入需要击中相同的路径。
但是使用这个约束来减短输入的长度并不够理想,放宽了这个约束可能会让输入更简短。
所以FAIRFUZZ的做法是不需要经过相同的路径,而是只要与原始输入达到相同的目标分支即可。
4 实现和评价
基于AFL加了600行C代码实现了FAIRFUZZ,一篇CCS。。这个不能让老板看到。。
在9个benchmark上实验。
4.1 与之前技术的覆盖率比较
AFL,FidgetyAFL和AFLFast.new作为baseline。
每个benchmark上跑24h,重复20次。
4.1.1 总体分支覆盖
Why branch coverage?。除了基本块转换覆盖(如branches),另一个常用的度量是评价路径覆盖。由于AFL事先问题,只有分支覆盖这个度量是鲁棒的。
举个栗子,有俩分支$b_1$和$b_2$,A hits $b_1$,B hits $b_2$,C hits both $b_1$和$b_2$。若输入的顺序是A,B,C,那么路径$p_A=\{(b_1, 1)\}$,$p_B = \{(b_2, 1)\}$,$p_C = \{(b_1, 1), (b_2, 1)\}$,找到的路径计数为2;若输入的顺序是C,A,B,那么路径的计数只有1。branches的计数总为2。
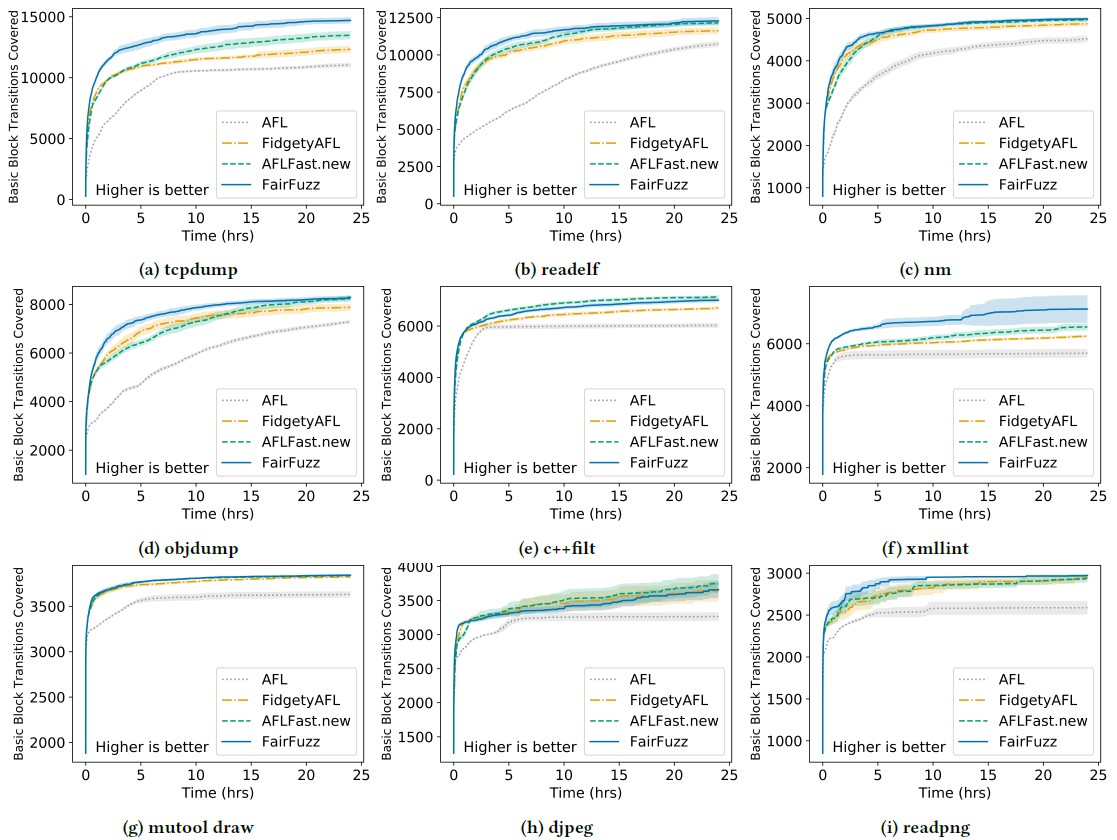
结果。除了c++filt的其他8个项目都是FAIRFUZZ效果最好。
4.1.2 覆盖差异的详细分析
4.2 masking是否可以有效地导向分支?
在FAIRFUZZ中添加shadow mode。该模式直接进行所有种类的变异而不考虑mask。
下表显示了使用确定算法变异和havoc变异阶段,目标分支的百分比:
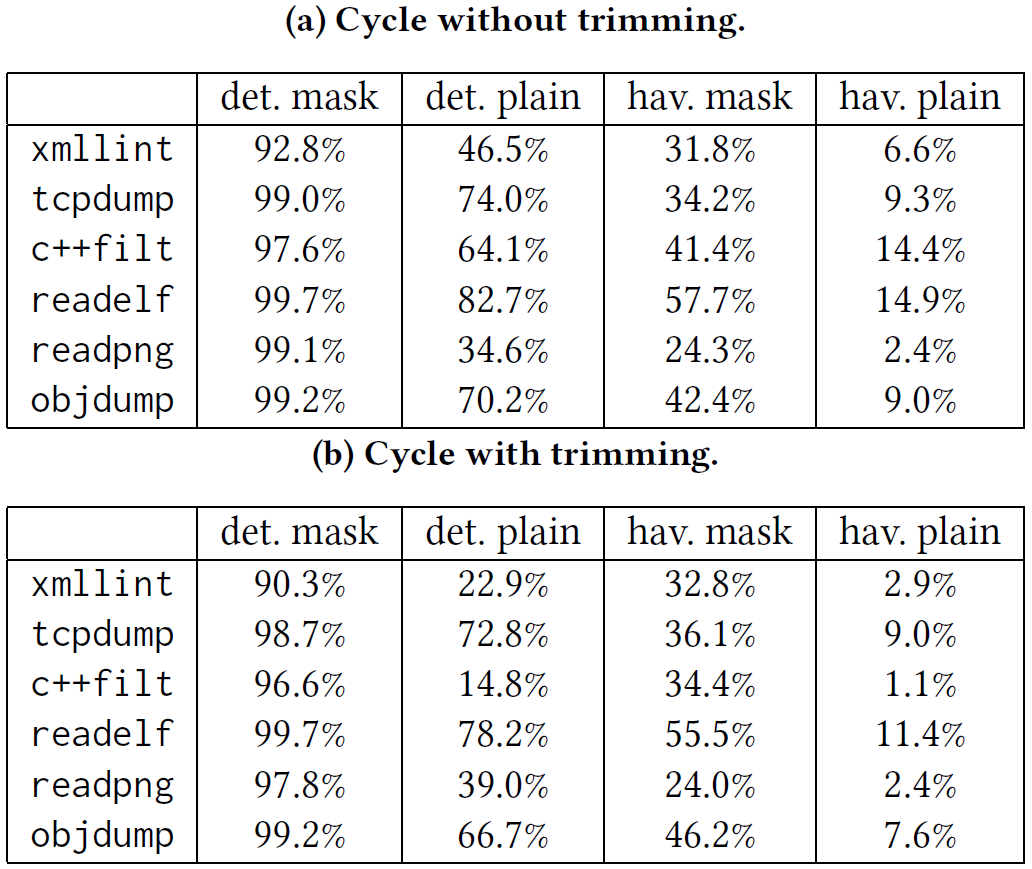
结果显示mask大大提升了变异输入hit target branch的百分比。
mask技术可以用来导向需要测试的函数所在的分支,或者代码最近修改或容易引发bug的片段等,这些场景下可以通过mutation mask来定位目标分支。
5 讨论
本工作的评价可能不适合泛化到其他项目
此方法不能以任何AFL到达不了的分支做目标,这很显然。。
FAIRFUZZ在xmllint这个benchmark上找关键词序列时很有效。这是因为parser.c使用CMPn这个宏,结构上和byte-by-byte比较相同,每匹配到一个新字符就会产生一个新的覆盖。