Fuzzing: a survey
介绍
模糊测试的概念第一次在20世纪90年代提出.
多年来的实践中表明传统的模糊测试只能找到程序运行初期的简单的内存冲突bug. 除此之外, 模糊测试的随机性和盲目性导致找bug效率低.
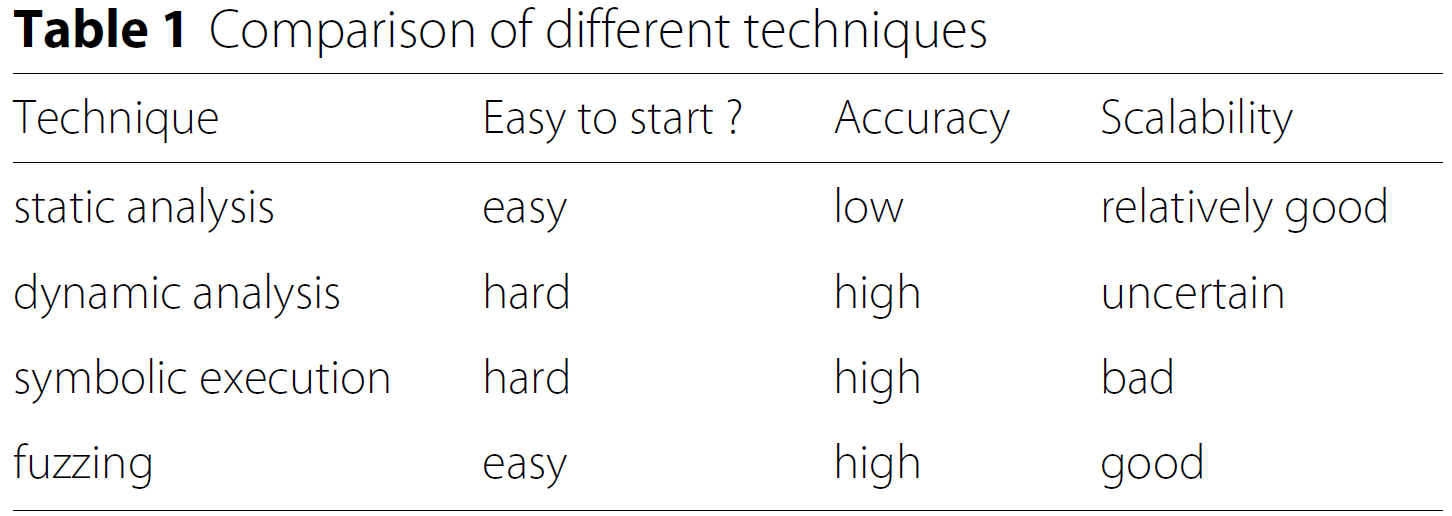
传统易损点检测技术
- 静态分析
- 优点: 检测速度块
- 缺点: 有很高的错误率, 存在很多假正例
- 动态分析
- 优点: 精确度高
- 缺点: 1) 动态分析中分析, 运行目标程序的步骤需要人工交互, 导致效率低; 2) 人工交互需要有丰富的专业技能; 3) 扩展性差
- taint analysis(污染分析?)
- 符号执行
- 路径探索的能力受限于约束求解器的能力
- 符号执行难以扩展到大型应用
- 模糊测试
- 优点: 易于部署, 有较好的可扩展性
- 缺点: 效率低, 代码覆盖率低
模糊测试
模糊测试的工作流
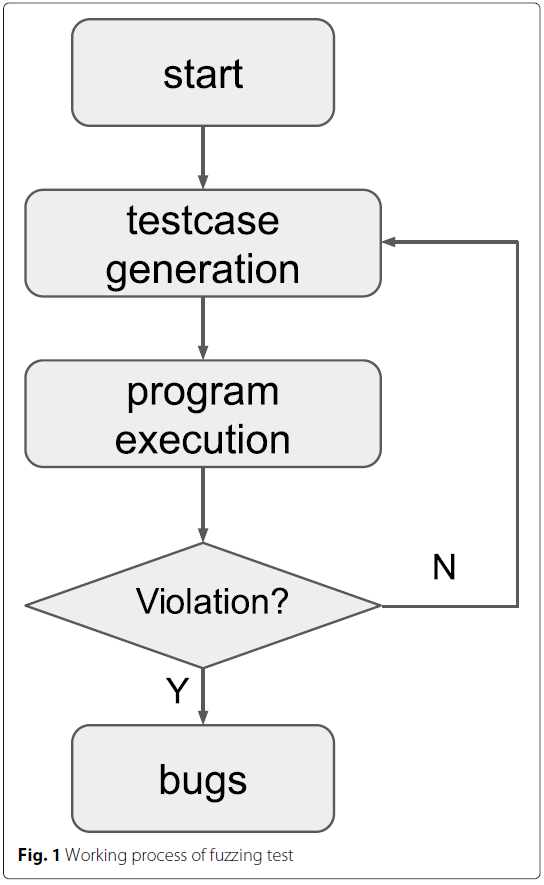
流程很简单: 不断生成测试用例调用程序执行, 如果出现错误或异常则认为是一个bug.
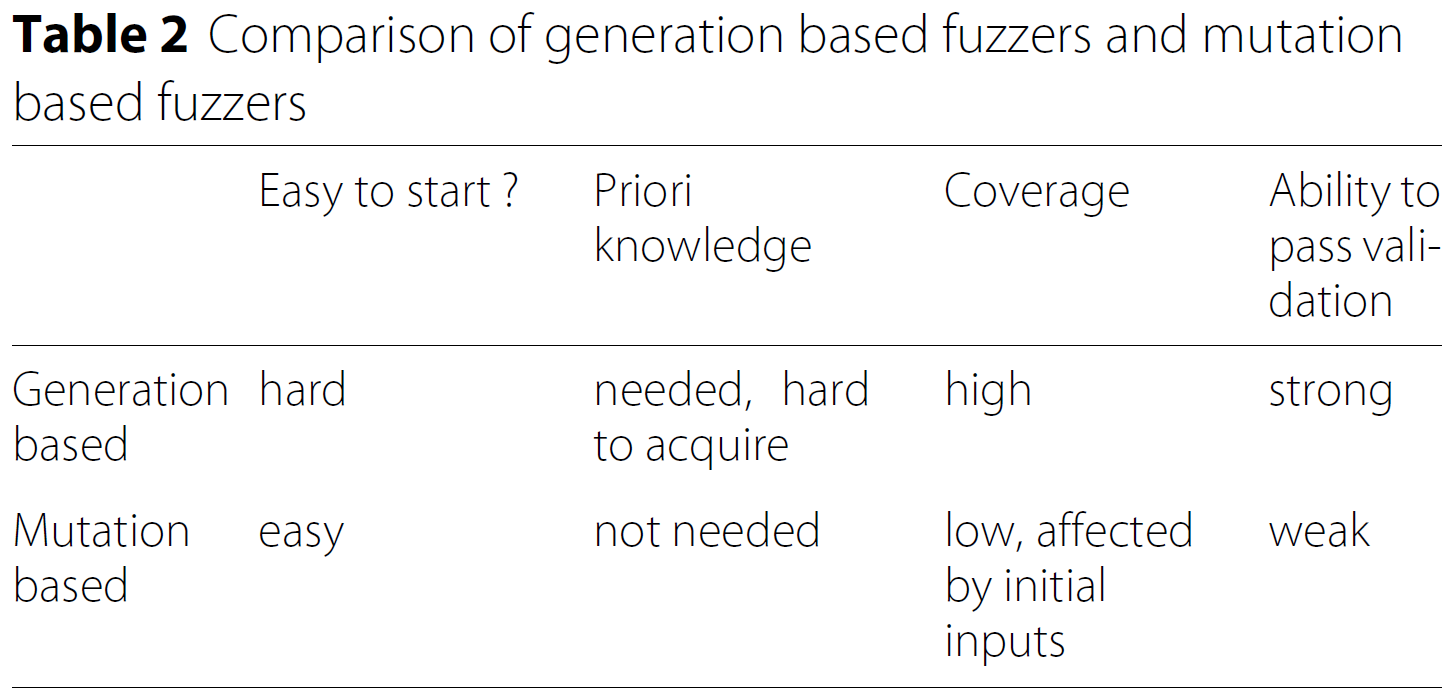
有两种常见的生成器:
- 基于生成的生成器
- 基于变异的生成器
模糊测试器的类型
1. 以生成方式分类
- 基于生成的生成器
- 基于变异的生成器: 基于变异的模糊测试器更容易使用, 广泛的应用在最前沿的模糊测试器中
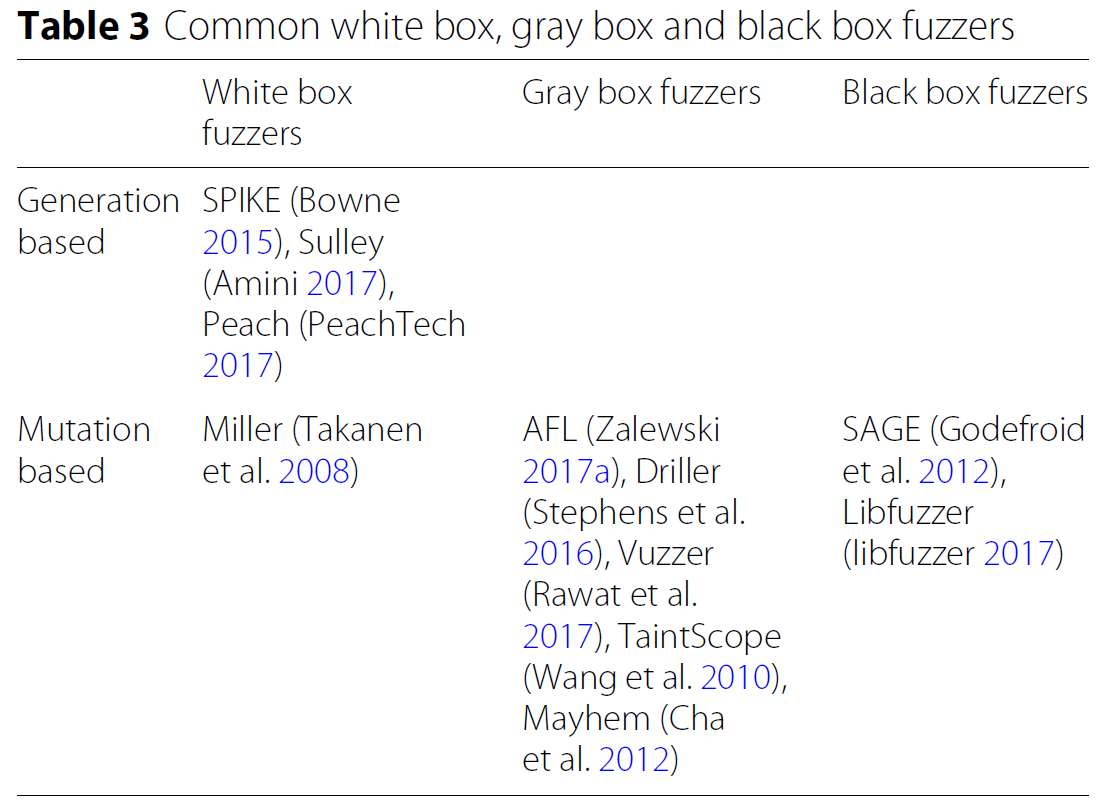
2. 以对于程序源代码的依赖程度分类
- 白盒测试
- 灰盒测试
- 黑盒测试
3. 根据探索程序的策略分类
- 直接fuzzing
- 基于覆盖率的fuzzing
4. 根据是否利用反馈信息分类
- dumb fuzz
- smart fuzz
模糊测试的主要挑战
- 如何变异种子输入, 变异包括 1) 在哪里变异; 2) 如何变异
- 低代码覆盖率
- 通过输入合法性验证的挑战
基于覆盖率的模糊测试
代码覆盖率计数
- 直接统计执行的基本块的个数
- 统计基本块之间转换的个数
给出一个例子:
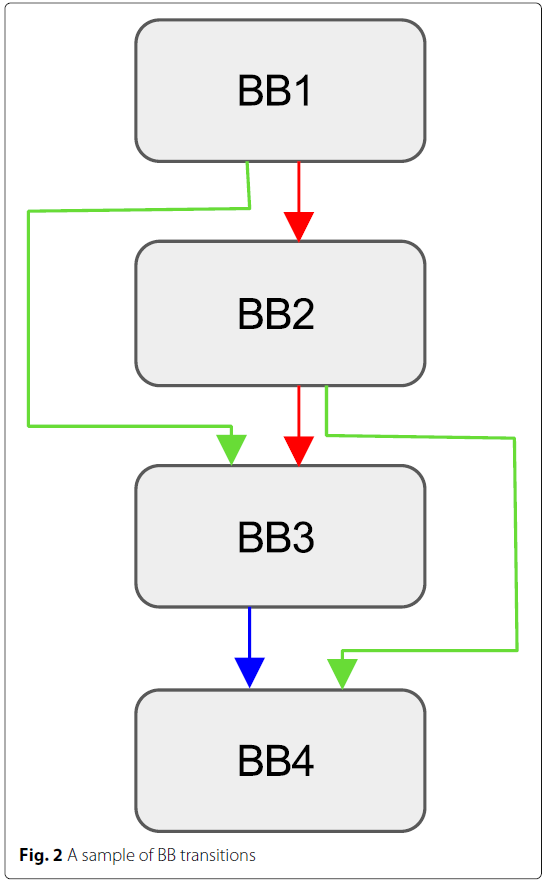
若路径$BB_1\rightarrow BB_2\rightarrow BB_3\rightarrow BB_4$已经执行, 若仅考虑执行基本块的数量, 则四个基本块都已覆盖, 会遗失了$BB_1\rightarrow BB_3$和$BB_2\rightarrow BB_4$的信息.
基于覆盖的模糊测试工作流
然后是个AFL工作流程图, 看就完事了:
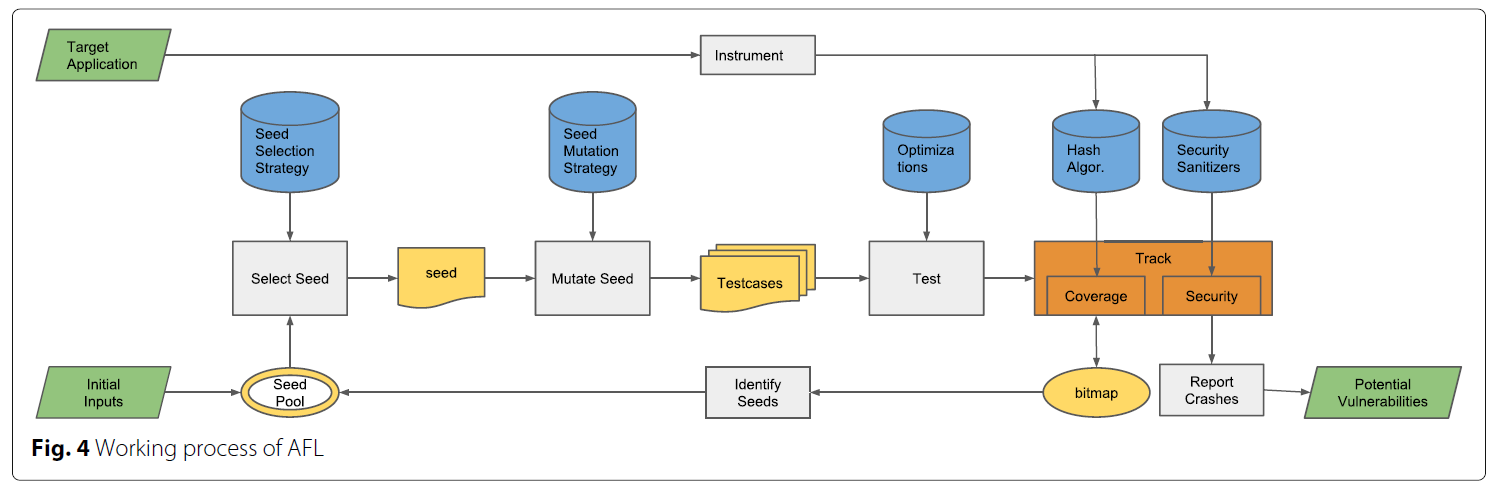
AFL的工作Mutation过程中, 除了会随机变异还会使用额外的有名的有趣的输入字典, 如整数中的0, 1, INT_MAX等…
主要问题
1. 如何生成初始输入?
好的初始输入应该另fuzzing高效且有效. 目前常用的方法是收集来自标准集, 网络上爬取和已有的字典的种子输入.
2. 如何生成测试用例?
好的测试用例可以探索更多的程序执行状态, 在尽可能短的时间内覆盖尽可能多的代码.
微软研究院使用基于神经网络的统计机器学习技术自动生成测试用例. 同时也已有研究也尝试使用GAN辅助重新初始化系统.
3. 如何从种子池中选择种子
已有研究证明好的种子选择策略可以有效地改进fuzzing效率, 加快找bug的进程.
可以考虑的做法:
- 有用的种子赋予更高的优先级, 如覆盖更多代码的种子和更有可能触发异常的种子
- 减少重复路径的执行
- 最优化选择能够覆盖更深和更有可能出现异常的种子
4. 如何有效测试应用?
创建和结束进程会耗费大量的cpu时间, 频繁地创建和结束进程会降低fuzz的效率. 传统系统特性和新特性用于优化过程. AFL使用forkserver的方法, 创建一个已加载的程序的克隆, 并在每个单独运行中重用.
集成在fuzzing中的技术
smart fuzz收集程序的控制流和数据流, 并应用这些信息改进测试用例的生成, 使测试用例生成更有目的性.
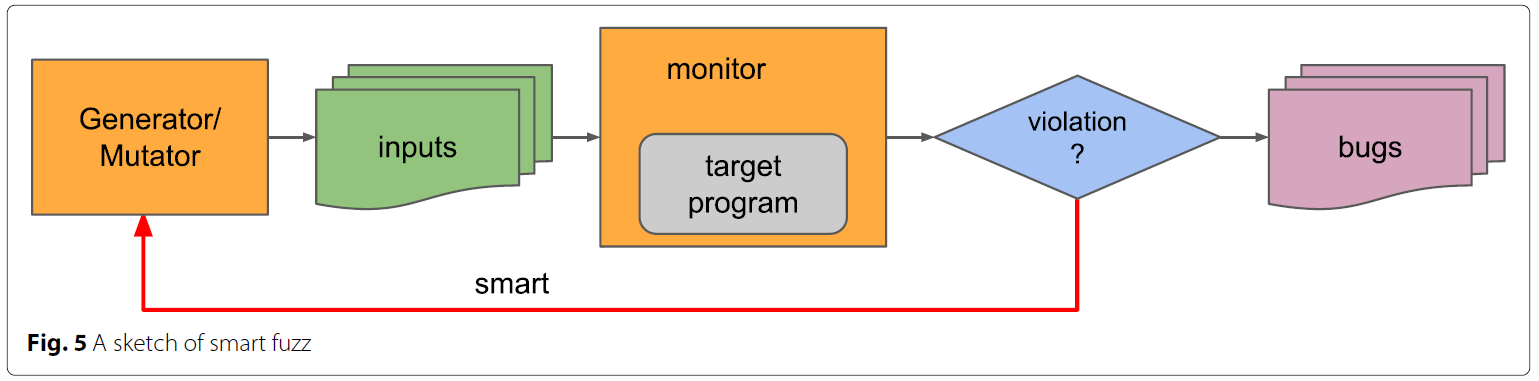
接下来选择两个重要阶段介绍如何改进fuzzing: 测试用例生成阶段和程序执行阶段.
测试用例生成阶段
在fuzzing生成阶段, 根据输入数据格式的知识生成测试用例. 尽管已有一些常用的文件格式开源提供, 但是更多地格式并没有提供. 如何获取这些输入的格式知识是个主要问题. 已有工作使用循环神经网络(RNN)解决这个问题.
很多已有的模糊测试工具使用基于变异的策略. 如何确定修改的位置和修改的值是另一个主要挑战. 微软的研究者使用DNN预测变异的字节和变异为什么值, 使用LSTM, 由于LSTM可以.
程序执行阶段
如何指导fuzzing过程和如何开发新路径.
fuzzing过程以覆盖更多代码和在短时间内发现更多 bug 为指导.
以是否提供源代码为依据分类, 可以分为编译内插桩和外部插桩.
使用静态分析技术收集控制流信息, 如: 路径深度.
通过插桩收集到的路径执行信息可以帮助指导fuzzing 过程.
使用符号执行技术可以获得达到程序点所需满足的约束.
已有研究也使用具体执行(concolic execution)技术绕过条件判断以找到更深的 bug.
面向不同应用的Fuzzing
文件格式 fuzzing
核 fuzzing
- 核fuzzing 在 crash 后会使整个系统崩溃, 如何抓取crash 是一个开放问题
- 系统的权力机制导致系统是一个相对封闭的环境, 如何与核交互是一个主要问题
- 广泛使用的核比如Windows核和MacOS 核是闭源的, 增加了插桩的难度.
核 API 函数的 fuzzing 存在两个主要挑战:
- 核 API 的参数都有固定的规格
- 核 API 的调用顺序应该是合理的
协议 fuzzing
两个主要挑战:
- 服务可能定义它们自己的通信协议, 很难得到具体的协议标准
- 即使是文档化的协议, 往往也很难完全遵循规格
fuzzing 的新趋势
smart fuzzing 提供了改进 fuzzing 效果的可能性, 即使用执行程序的反馈信息指导测试用例生成balabala…
新技术帮助改进 fuzzing, 如 ML 和 DL 技术.
- 考虑使用新的系统特性和硬件特性.
总结
这篇文章概括了近几年的 fuzzing 进展. 首先, 本文将 fuzzing 与其他攻击点发现技术作比较, 然后介绍了 fuzzing 的技概念和主要挑战. 之后主要介绍了最先进的基于覆盖的 fuzzing 技术. 最后, 总结了 fuzzing 的继承技术, 和今后新的发展趋势.