Sentiment Polarity Detection for Software Development
摘要
在开发者交流频道的数据集上训练的专用分类器Senti4SD (4SD = for software developers?).
1 介绍
现成的(off-the-shelf)情感分类工具与用户表达的观点不一致,甚至相悖.
另一个挑战是解决错误将中性文本分类为消极文本.”What is the best way to kill a critical process”和”BI am missing a parenthesis but I don’t know where”中”to kill”和”missing”在SentiStrength词典中包含负面语义.
本文提出情感分析分类器Senti4SD,基于词典,关键词和语义特征词嵌入的方法.负类分类的精确度上升19%,中性的召回率提高25%,与SentiStrength相比.
Senti4SD在4,423个Stack Overflow的post上构建.
2 研究方法
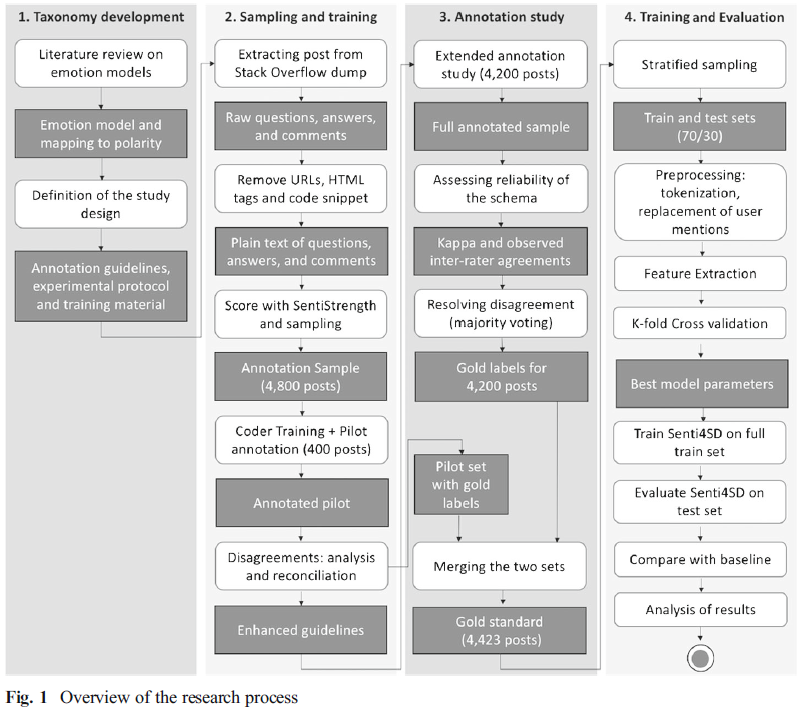
3 背景
3.1 情感模型
理论基于认知心理学和自然语言交流,两种观点进行交融:一些人认为情感是一个基于一维或多位的持续函数,另一些人认为情感是一个基础情绪的有限集合.
支持连续观点的人认为情感状态从两方面建模 1) 情感极性; 2) 激励程度;
支持离散观点的人认为有限的基础情绪的集合是存在的.
3.2 基于SentiStrength的情感极性检测
SentiStrength将每个词进行打分
积极:[+2,+5]
中性:{-1,+1}
消极:[-5,-2]最后分别找到两种极性的最大值, 代数加和, 输出整体的情感极性(positive - 1,neutral - 0,negative - -1).
3.3 Distributional Semantic Models (DSM)
DSM是在高维向量空间上表征一个数学点的模型.
最传统的就是用词频表示一维,然后进行降维,降维用LSA处理,LSA是将现有高维特征进行奇异值(SVD)分解.
今年流行的方法是word embedding,使用fixed dimension表示词.
本文使用Mikolov在2013年提出的方法训练词向量 1) Continuous Bags-of-Words (CBOW):通过上下文预测目标词汇 2) Skip-gram模型通过当前词汇预测上下文词汇.
4 数据集
从Stack Overflow上提取的4,423个post.这个数据集是平衡的,35%positive,27%negative,38%neutral.
4.1 构建标记数据集
- 提取2008至2015年的post,使用正则表达式去除html tags;
- 已有研究表明情感在评论中比在问题或答案中表达更强烈,每个post抽取的内容除了问题和答案,还包括评论;
- post {question,answer,question comment,answer comment} -> emotion {positive,neutral,negtive};
4.2 pilot annotation study & 4.3 Emotion Polarity Coding: Extended Study
12位程序员参与情感极性标注.
- 使用25个post解释情感标注的流程;
- 12个人分为4组,每组100个post,一共400个,一周时间用来训练如何标记;
- 每组500个post,一共2000个新的post,三周时间标记,加上步骤2一共得到2400个数据点;
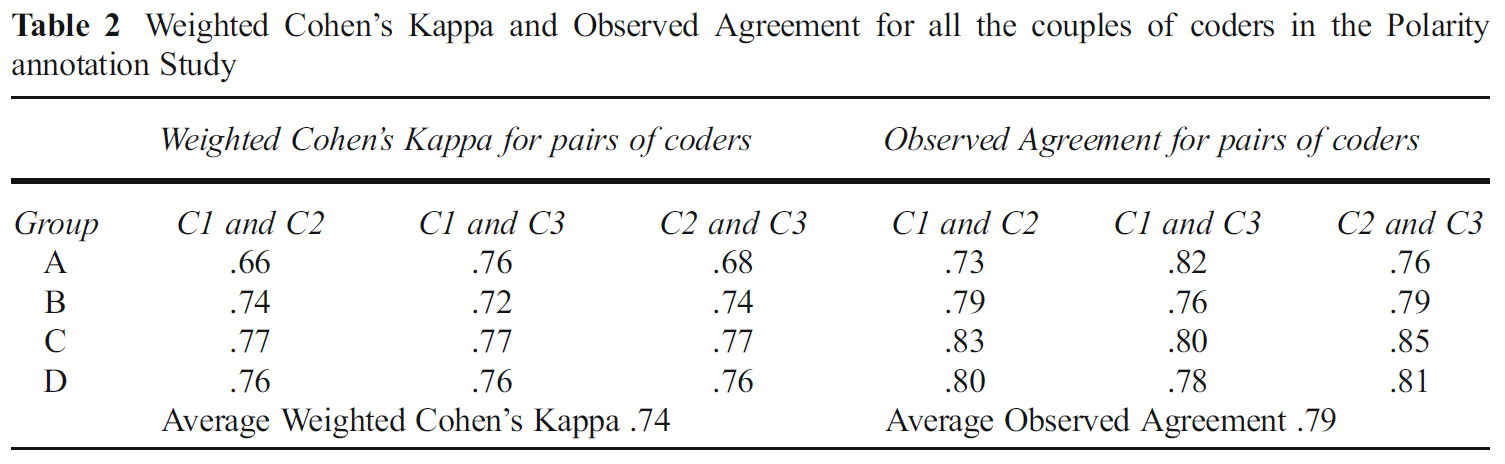
- 计算weighted Cohen’s Kappa计算标记的一致性;用observed agreement辅助计算;
5 情感极性分类器:特征描述和系统设置
结合通用特征和领域相关特征可以改进情感分类的效果.
使用三类不同特征:
- generic sentiment lexicons(通用情感词典)
- keywords(n-gram)
- 在训练集上训练得到的DSM
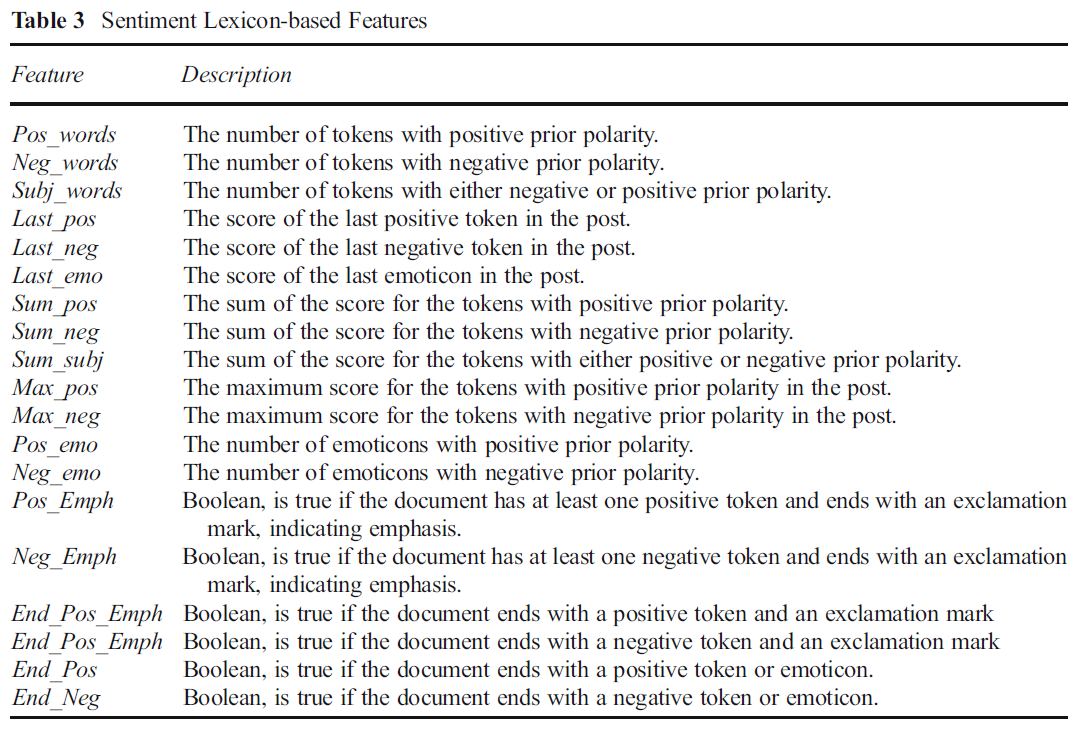
5.1 基于词典的特征
完全基于给定的词典
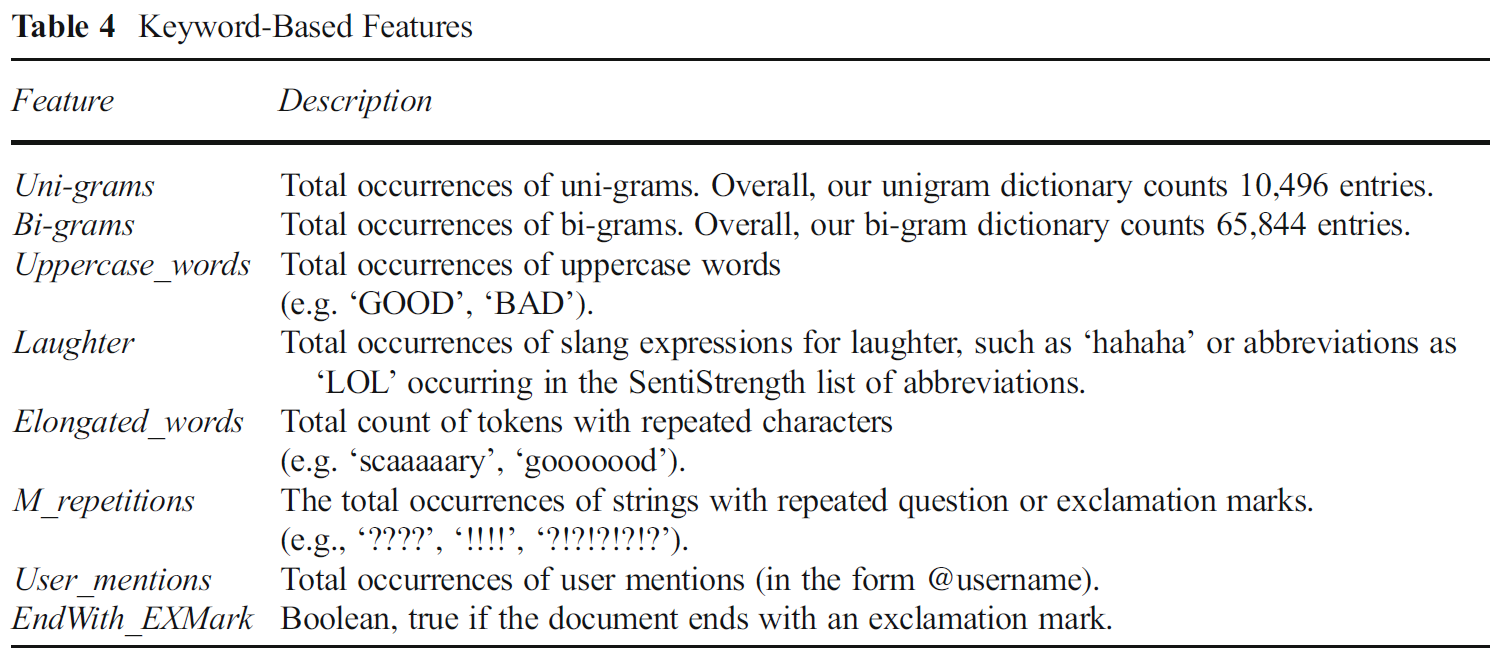
5.2 基于关键词的特征
实验中仅考虑unigram和bigram.
5.3 语义特征
prototype vectors表示情感类型的向量.
使用文档中所有词的向量和表征一个文档.
这里的做法是, 对于某种情感极性(positive, negative, neutral), 选择对应情感极性的所有词向量相加. 另外计算所有positive和negative的词向量的和以区分neutral. 这4个向量用来计算语义特征, 也就是说文档向量和每个原型向量的相似度.
实验中使用SentiStrength词典中标识的词. 数据集大小为3.8million问题,总计5.9million回答和11.6million评论,训练600维的向量.

5.4 实验设置和调参
实验中将@替换为@USER. 处理不包含词根化或词性还原, 因为他们可能会影响极性的重要信息. 同时不去除停止词, 与已有研究保持一致.
本文使用使用SVM模型训练分类模型. 线性SVM是当前最好的在高维稀疏数据集上的分类模型.
在有监督的文本分类任务中, 很少特征会是不想管的, 所以不进行特征选择, 而保留所有特征.
对于线性SVM, 取较大C值会给错误分类更大的惩罚, 但是可能会造成过拟合. 所以在训练集上进行十折交叉验证优化C值.
对于训练词向量, 向量空间维数尝试{200, 400, 600 ,800, 1000}.
最后对于很少出现和频繁出现的词分别进行直接删减和降采样.
6 评价
6.1 训练集和测试集
70%训练集, 30%测试集.
6.2 结果
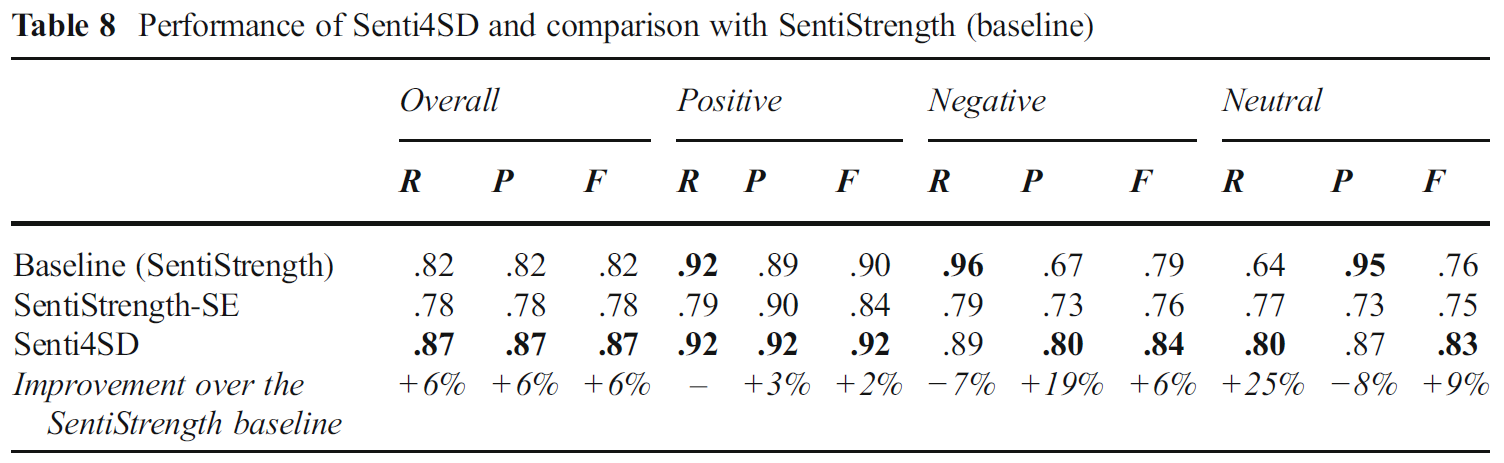
SentiStrength和SentiStrength-SE得分映射关系如下:
- 若$p+n > 0$, 则为positive;
- 若$p+n < 0$, 则为negative;
- 若$p+n=0$且$p<4$, 则为neutral;
- 若$p\geq 4$, 则认为语义不明, 要从数据集中舍弃.
实验结果表明在负类精度上有19%的提升, 中性召回率有25%的提升.
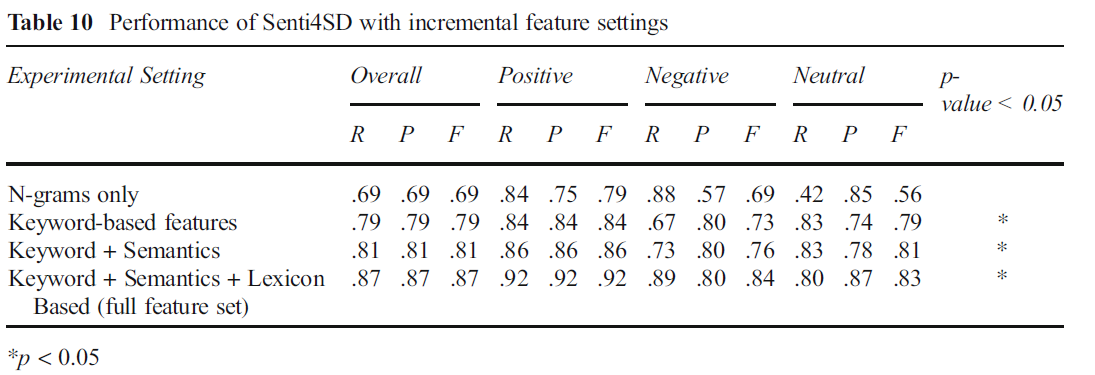
检验性能提升是由于使用了机器学习技术还是增加了额外的特征.
结果显示仅用n-gram语言模型F=0.69. 为了解决negative R=0.67和F=0.73, 引入semantics features, 为了解决negative R=0.73, 引入lexicon features.
7 讨论
与SentiStrength比较
SentiSD解决了negative bias的问题. 但是精度的提高的代价是negative类召回率的降低 -> 从0.96下降到0.89.
启示
在实现情感分类器时, 决定根据精度优化还是召回率优化是很重要的, 这取决于应用场景.
定期检测合作者的负面情绪可以协助检测代码的违反行为和进行有效的社区管理.
情感分析工具在挖掘软件仓库中很常用.
特征上的贡献
这个工作没有进行特征选择, 而是包含了所有基于词典, 基于关键词和语义信息的特征.
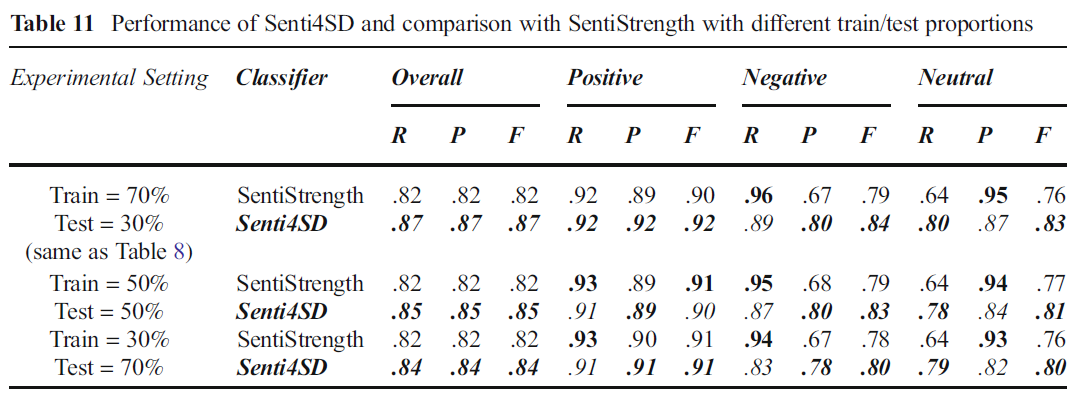
通过特征的信息增益分析影响较大的特征, 使用Senti4SD在不同特征设置上进行比较. top-10的重要特征都属于基于词典的特征. 紧接着的4个特征是语义特征. Pos_emo和Neg_emo是基于关键词的两个重要特征. 表11说明Senti4SD实现的有监督学习在不同规模的测试集上的性能表现差异不大.
Gold standard(数据集?)
提供了一个人工标记的在Stack Overflow上构建的情感分类资源.
8 Threats to Validity
- 情感标注是一个主观的过程, 可能会引入误差. 为了减少或消除这种误差, 实验中给出了明确的情感标注的指导. 数据集排除了所有情感极性相反的用例. 评分者间一致性(average weighted Cohen’s Kappa)达到0.74, 可证明标注足够可信;
- 文中使用
SentiStrength对于所有数据进行第一步的情感分析和采样, 使得数据集中每种标签的实例数量平衡. 但是之前的研究表明SentiStrength在软工领域的效果并不好, 尤其是它经常将neutral分类为negative, 同时也会将positive分类为negative, 导致采样得到的数据集经过人工标注后negative数据点会偏少, 实际的结果也是如此: 35%positive, 38%neutral, 27%negative.
9 相关工作
9.1 软工中的情感分析
9.2 软工中的离散语义(word embedding)
10 总结
本文提出了Senti4SD, 在4k数据上训练和测试模型, 数据集开源, 放出标记指导.
在20millionStack Overflow文档上通过word2vec构建DSM, 并开源.
与现有的语义分析工具(SentiStrength)相比, 在negative分类上的精度提高19%, 在neutral分类上的recall提高25%.